Companion to Atom
Work in progress. By Sam Ruby
Preface.
Let's face it. You are a busy developer. You see a small and relatively straightforward specification for a syndication format, but you see that it makes references to any number of other standards, some IETF, some W3C, some ISO, etc., and each appears to be deceptively simple. However, if past experience is any guide, you know that there be dragons in each.
What makes things worse is that most of the specs are extensible, and yet there never seems to be a comprehensive list of extensions.
This guide is meant to be a companion to the Atom 0.3 specification. Over time it will evolve with the specification and expand to cover the API. And while the list of extensions covered by this document will never be complete, the plan is to make this a living document and cover all the common variations seen in the wild, and provide targeted references (i.e. deep links) to specifically relevant sections of other documents when required.
This guide is also meant to be a reference, meaning that you can quickly get in, find what you need, and get out.
HTTP GET request
So, lets start at the beginning. An Atom syndication feed is an XML 1.0 vocabulary transmitted via HTTP. Lots of buzzwords in that sentence, eh? Dont worry about it, we will talk you through it, and provide lots of examples. In fact, here is the first:
GET /blog/index.atom HTTP/1.1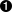
User-Agent: Python-urllib/2.0a1
Host: www.intertwingly.net
If-Modified-Since: Thu, 08 Apr 2004 13:26:16 GMT
If-None-Match: "1d41ae-1ba0-3940ae00"

This is what an HTTP request looks like. Many of you may have never seen one of these before, as it has been taken care of for you by some library routine for you. And like a modern calculator, that library routine probably has more buttons, options, bells and whistles than you ever have had a need for. And as you are a busy developer, you typically dive right in and figure you will fix problems as you encounter them.
Well, there are a lot of libraries out there, and there is no way that I can know every one of them. But I can walk you through what a request looks like, what is important, and what is not. Hopefully once you know what is important, you'll know what to look for, and then hopefully you can find the right option to enable on your library's API.
OK, I know that you are busy, so lets get on with it.
GET
is an HTTP method. It means that you are
requesting a representation the resource identified via a Uniform
Resource Identifier. If this doesn't mean anything to you, dont
worry about it, it simply means GET.
/blog/index.atom
is the resource on this site that you are requesting.
It always starts with a slash, always is URL
encoded. Yes, that is another standard
that you need to worry about. We will
get to that shortly, but if you are impatient, you can go there
now.
The User-Agent
identifies what software you are using to retrieve this feed. Get this wrong, and your request may be
refused. Putting something meaningful
here is a sign that your software plays well with others.
The example provided above is mediocre at
best. You can do better.
This
identifies which host you are sending this request to.
This may seem obvious, I mean, shouldn't the
receiver already know who they are? The
simple fact is that many hosting services support a number of virtual
hosts, and this information is required in order to properly
route the request.
If-Modified-Since
and If-None-Match are headers which should be included on
every request
after
the first one. More explanation is
provided below, but suffice it to say that not including these headers
is
considered to be extremely rude and will waste considerable time and
bandwidth
for both you and the recipient of the request.
The Accept-Encoding
header gives the server permission to compress the response if it
chooses to do
so. If you can handle decompressing the
response, this is a good thing to do.
Description of compression techniques is beyond the scope of
this guide (see gzip
and deflate for
more). If you dont find an obvious way to support this, dont
worry too
much
about it, as it is optional.
 Headers
terminate by a blank line. More
specifically, a series of four characters: carriage return, line feed,
carriage
return, line feed. In decimal, this is
13, 10, 13, 10. In hex this is 0D, 0A,
0D, 0A.
Headers
terminate by a blank line. More
specifically, a series of four characters: carriage return, line feed,
carriage
return, line feed. In decimal, this is
13, 10, 13, 10. In hex this is 0D, 0A,
0D, 0A.
There are more headers, but this should be enough to get you started. The most significant omission is authentication, which deserves its own chapter. Most feeds are not password protected, so you likely can get away without knowing about this for a while, but if you really need to, feel free to jump ahead.
Of the seven bullets described above, most libraries get 1, 2, 4, and 7 right, do something mediocre for number 3, and completely omit numbers 5 and 6 by default. This means that most clients are rude by default. Dont be a rude client. Not only will the servers you access appreciate the reduced bandwidth bills, but you will find that your client is more responsive.
HTTP GET response
If things are set up correctly, the majority of responses your application receives should look something like this:
HTTP/1.1 304 Not Modified Date: Thu, 08 Apr 2004 14:15:03 GMT Server: Apache/2.0.46 (Red Hat) Connection: close ETag: "1d41ae-1ba0-3940ae00"
In such a response, the essential piece of data is the status code. It appears on the first line, and in this case is a 304, which means Not Modified, a message that is reinforced by repetition of this code in human readable form.
Depending on the status code you receive, there may be little need to look at any of the other data. And that is certainly true in this case.