Capacity Planning for Multi-Tenant SQLite Applications

Capacity planning is hard when you have multiple users with SQLite databases, users are pinned to specific machines, and there are hard memory limits. As the number of users grows and regions are consolidated, I need to reconsider my capacity planning strategy.
Here's the topology of my showcase application:
- Each user is a dance studio, and each dance studio has multiple events (past, current, and future).
- Each event is a separate tenant with its own database and its own instance of the same Rails application.
- All tenants for a given user are on the same machine.
- Multiple users (and their tenants) are assigned to the same machine.
Currently, I have 70+ users distributed across 8 machines. At the moment, sjc and iad are the most concentrated regions.
Puma is configured to three threads per tenant. Individual tenants (Rails applications) are shut down after five minutes of idle. Machines suspend at thirty minutes of idle.
All machines are provisioned with 2GB of RAM and bad things happen (OOM kills, performance degradation) when that limit is reached. The concern is that with multiple tenants on a single machine, memory will run out.
What's Working
Below is a screenshot of memory usage over during an event in Virginia Beach this weekend:
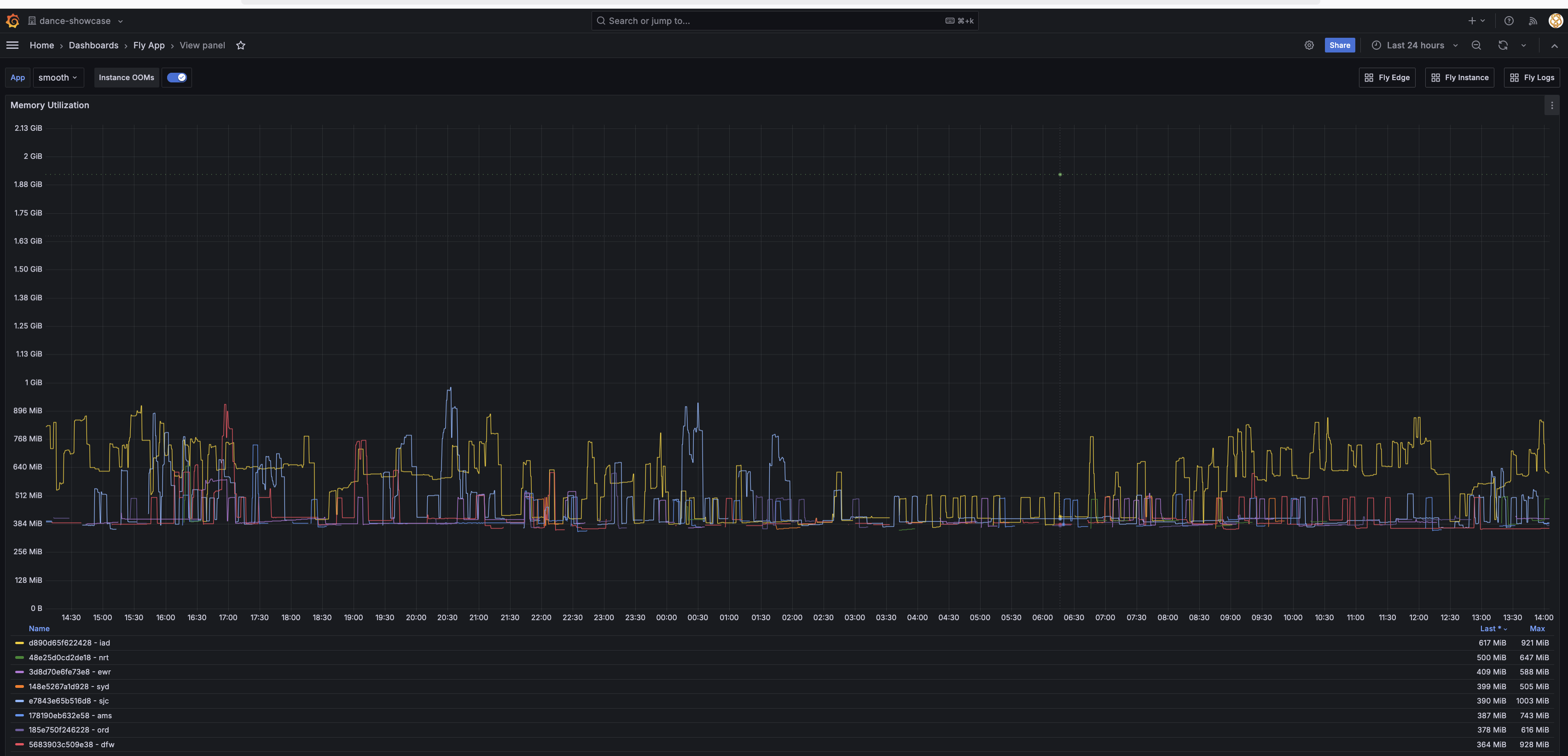
The suspend support from fly.io is working well: not shown here but on other days there are even brief periods of time when there are no machines running. Every machine listed below the graph was active at some point during this 24 hour period. The average overall is around 2 to 3 machines active at any point in time, and slightly less on weekends.
Many requests may be web crawlers which I try to either reject with HTTP 401 Unauthorized responses or serve them statically. My robots.txt is fairly strict, but not all web crawlers honor it.
I've stress tested Web Sockets and concluded that each active Web Socket consumes less than 100KB of memory, so 500 simultaneous connections would require less than 50MB of RAM. Web Sockets aren't a significant memory concern.
The application uses jemalloc as an alternative memory allocator (via LD_PRELOAD in the Dockerfile) to reduce memory fragmentation when running multi-threaded Puma. This is particularly important for Rails applications with multiple threads, as the default Linux memory allocator can lead to significant memory bloat over time.
Options Being Explored
The direction I am exploring is adding more machines, potentially even one per user, and perhaps even dropping memory to 1GB. If a single user exceeds that, their individual machine will reboot with an OOM error and reset. No other user will be affected.
Perhaps that is too far. There are some processes that have overhead per machine - deploy being one of them, but currently updating user passwords or adding new events also require at least awakening every machine, though some of this could move to start and restart hooks. And there are other indirect costs. When there is only one machine in a region, fly.io's proxy has better chances of routing to the right machine when processing requests. Injecting fly-prefer-region and fly-prefer-instance-id headers mitigates this considerably.
I've tested per-tenant memory limits within Navigator using Linux cgroups v2, but unfortunately I can't get it to work on fly.io. This would allow the kernel to OOM kill and automatically restart only the offending tenant when limits are exceeded, keeping other tenants on the same machine running normally. Based on typical Rails 8 + Puma memory usage (300-400MB baseline), a 512MB default would have allowed 3 active tenants per 2GB machine, with tenant-specific overrides for smaller or larger events.
For Docker-based deployments like Kamal on VPS/bare metal, adding privileged: true and cgroupns: host to the server options in deploy.yml should provide cgroup access, but I've yet to test this configuration.
I also know when each event is, so I could periodically rebalance machines so that very recent and upcoming events are placed on separate machines, with historical and distant future events clustered more densely.
I don't have a solution yet - this post is mapping out the possibilities to organize my thoughts as I evaluate the trade-offs.
Update: October 13, 2025
The per-tenant memory limits are now working on Fly.io! The issue was that Fly.io runs a hybrid cgroups configuration where cgroup v2 files exist but cgroup v1 is actually active.
The solution was implementing automatic detection that checks both:
- Whether
cgroup.controllerscontains "memory" (it does on Fly.io) - Whether
cgroup.subtree_controlhas memory enabled (it doesn't on Fly.io)
When v2 is available but memory isn't enabled in subtree_control, Navigator now falls back to cgroup v1 at /sys/fs/cgroup/memory/. This works perfectly on Fly.io:
$ ls /sys/fs/cgroup/memory/navigator/app/
cgroup.procs memory.limit_in_bytes memory.usage_in_bytes ...
$ cat /sys/fs/cgroup/memory/navigator/app/memory.limit_in_bytes
536870912 # 512 MiB
$ cat /sys/fs/cgroup/memory/navigator/app/cgroup.procs
726 # Puma Rails server PID
This provides true memory isolation per tenant without requiring privileged containers or host cgroup namespace access. When a tenant exceeds its limit, only that Rails process gets OOM killed and automatically restarted, while other tenants on the same machine continue running normally.
For systems with full cgroup v2 support (where memory is enabled in subtree_control), Navigator will use v2. For hybrid or v1-only systems, it automatically uses v1. The implementation is in the feature/per-tenant-memory-limits branch.